
… or the problem “the system will handle it”. Something I’ve recently came across that had “deja-vu” all over it.
One of the SDK I’ve been working on had a nasty little screen hidden within it. One that is easily overlooked due to a wide variety of factors.
This is about the mobile device and… disk access.
The problem
One of the SDKs had a terrible effect on the CPU and disk performance. Both of those were through the roof. CPU easily reached 60% and the disk utilisation was beyond 35MB/s in a constant manner.
So you have one of those high hard disk utilisation issues. For no apparent reason your code burns through the hard drive and CPU like crazy. In my case it was an externally-provided SDK and I really wanted to know why. With no access to the source code all that is left is… de-assemble and hack or… build a similar, albeit smaller version, of the same SDK you’re going to be using (with a smaller set of functions – we’re not gods yet). Being lazy I’ve opted for the latter and decided emulate the problem on a separate application to better outline the issue to the original provider.
I’ve worked around the general functionality of the SDK. I knew, in general, what the SDK was supposed to be providing. I had access to the files it created and I could see the data it stored. A CoreData library filled with floating-point values. So I’ve decided to build something similar. Below you can find, in large general strokes, the steps I’ve taken.
This omits a lot of the basics of handling Core-Data. Which should have its own blog. Because it’s cool. Yes. Core-Data is cool. There… I’ve said it.
Down the memory lane

/insert an old fart’s ramblings here:
You see… back in the olden days when storing uncompressed audio was a serious endeavour we had a thing called “hard drives”. I mean we still do but their presence is somewhat hidden from us. A hard drive was a floppy disk on steroids. Without a hard drive a modern operating system would simply not work (like an “L” unit in Futurama). Having a reliable and fast hard drive made your life easier and more pleasurable (to whatever extent you’ve allowed it to be that is).
A nice addition to making your life marginally better was the sound it made. Something you could always hear when the drive was in operation. In the usual case scenario the drive would be spinning thanks to an electric motor (unless the drive was in sleep mode and thus the motor would be stopped – doh). Now – when a program wanted access to a specific portion of the disk a second motor would be activated and would align the drive head to a specific position. Then a read or write operation was performed.
And, as said before, you could almost always hear it. The more data was stored the more sound would be produced. The more fragmented the drive was the bigger the distance the drive head would have to travel for each consecutive operation (let’s leave cache out of it for now…). You could hear the actual disk operation and you could roughly gauge the level of fragmentation.
Why is this important now? We usually use SSDs. They’re wonderful. They’re silent. You never hear them. You can fill up your hard drive up to its capacity in a blink of an eye. In a normal mobile phone usage scenario – the one in which you’re the poor end-user and not the super-power enabled programmer, you don’t know exactly what’s happening to your device. Unless you’re an optimisation freak in which case I applaud you comrade. Your assumption, just like mine, is that the developer took time to optimize their code and treat the SSD in your mobile phone/personal digital device with respect.
Sadly this doesn’t always happen. As is this case here.
The scenario
We’ll be running a simple scenario here. We’ll be receiving data from the operating system and storing it in a database. In this case we’re gathering (x,y,z,timestamp) values from the accelerometer. The basic set of assumptions is as follows:
- We will be provided a single set of data at undetermined intervals
- Each entry will be structured in the same way, namely: it will be a set of four doubles
- The interval, at which we will be provided the data, might vary but we should be getting roughly 50 – 200 items per second
- We need to store the given data in a database for future reference
- We use Swift and CoreData (because we’re lazy that’s why!)
Each item might be presented as a structure:
struct Item {
let p1: Double
let p2: Double
let p3: Double
let timestamp: Double
}and will be mapped and inserted to the database. The structure itself should take around 4*64b (bits). No biggie. My old Atari could do that much.
In any case — the easiest course of action would be:
.observe_on_receive -> map() -> insert_to_database() -> save()(CoreData and basic database handling is beyond the scope of this post; see CoreData at developer.apple.com)
So we write our little program, gather data, save as soon as possible so we do not lose track of any data we might receive. We also do not introduce any bugs (professionals never do… cou*h).
And then we get this…
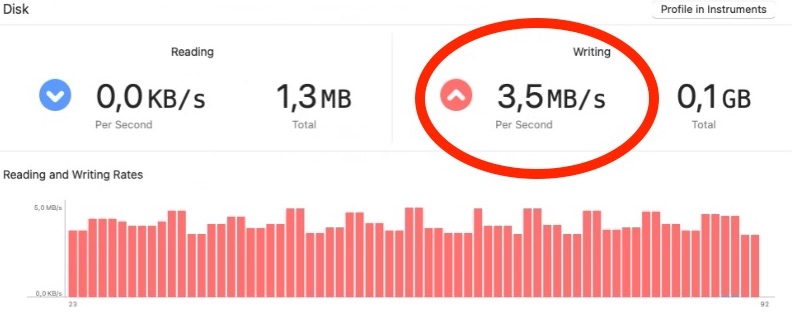
I mean what happened? How can this be? (you say to yourself in an unusually high-pitched voice). Are you really storing 3.5MB of data on disk? Is this the amount of data we receive from the OS? Have our calculations been… off? God forbid just plainly wrong?
You go into freak mode. You trace back your steps.
A single entry on a modern, 64-bit iOS device, in Swift, should be of size:
4 * sizeof(double) = 4 * 64b = 4 * 8B = 32BAnd a pack of 100 of those would be (roughly):
100 * 32B = 3200B ~ 3KBSo what’s happening here? We’re literally gathering around 3KB of data during the course of 1s and yet Xcode shows we’re saving around 4 megs… On top of that it screams that this level of interaction with the SSD might shorten its lifespan 😱.
Unpacking it all
So you regain your senses and you remember… you’ve been there before. And a short electro burst in the neurons later you realise you’ve missed a rather crucial piece.
You’re are getting 200 items per second and you store those 200 items to the database as soon as they come meaning you have 200 interactions with the database during the course of 1s. Not on every second but 200 individual inserts and database saves spread across the 1s time-window.
The graphs shows constant disk usage and is close to the truth. Each time the insert is made a save is made also. This means the database does all it usually does during a save. That includes physically inserting the data, re-arranging the data as needed and, sometimes, in the case of CoreData or Sqlite3 – vacuuming, meaning empty spaces are being cleaned and filled.
If we’d use some sort of database wrapper that hides the real machinations of the database from us the problem might be less of an issue. But we’re using something close to how the database is actually working. And this means we’re overusing the database saving procedure.
On top of that you remind yourself that HFS+ and/or APFS is a journaled file system. Meaning that upon a save operation it tries to create a new file, save data there, and then just… exchange the two (*file-based journaling) upon each insert operation (that’s more tricky than that but… nvm). This shouldn’t matter too much as the file system should be inteligent enough. And in any case there’s little we can do about it (for now).
But surely there’s something we can do. Perhaps if we’d decided to have some sort of buffer that would shield us from constantly needing to access the disk this might not have happened? Maybe if we inserted the data in a batched way it would somehow fix all of our problems?
Let’s see what we can do to make this problem go away.
The Buffer
For the sake of this example we will be build a simple Database Connector that will handle inserts and saves for us. We want to store a number of items in a buffer before actually going forward with the save.
final class CoreDataManager: ObservableObject {
private var bufferSize: Int
private var buffer: [Item] = []
}Instead of physically accessing the database the moment we receive the item from the OS we’re going to store it in the buffer… for safe keeping. We have an arbitrary, for now, buffer size, overflowing of which will cause the buffer to be inserted in the database.
So now the process will look a bit different.
.observe_on_receive -> map() -> push_to_buffer()
if sizeof(buffer) > BUFFER_MAX_SIZE {
insert_to_database() -> save()
buffer_drain()
}Only when the buffer overflows (gets too big) do we trigger the save. We’re essentially using RAM as an offset and postponing the hard-drive operation.
RAM will always be faster than the hard drive. Granted this may change in the future but for now the old paradigm still stands: store in RAM often, save to hard drive infrequently.
(I would add that: in an ideal world – don’t store in RAM often and never use the hard-drive but that’s for another ramblings post)
So a simple buffer-appending operation might be presented as:
private func _pushData(
_ p1: Double,
_ p2: Double,
_ p3: Double,
_ timestamp: Date
) {
self.buffer.append(
Item(
p1,
p2,
p3,
timestamp: timestamp.timeIntervalSince1970
)
)
if self.buffer.count > self.bufferSize {
_storeAndDrainBuffer()
}
}Et voila!
The Batch Insert
Another crucial part is… batched insert. Databases are complicated machines. In our case the data is simple. In reality data from different entities might be connected with others. Some data might be indexed. All that makes the machinations of the database the complex ones.
To help facilitate inserting of the data we generally should pack our stuff into batches and insert them as one.
In the case of Sqlite we would use transactions. Those group the operations in one pass, which in turn can give you the ability to undo, should you need that. One thing to remember is: there might be a magical limit to the number of operations that could be grouped in one go so… be mindful and… use a buffer!
BEGIN TRANSACTION
// do your inserts
COMMIT TRANSACTIONIn our case though, since we’re using CoreData, we might just as well use the batch insert request:
private func _storeAndDrainBuffer() {
print("Draining buffer")
moc.performAndWait {
let mapped: [[String: Any]] = self.buffer.map { item in
return [
"p1": item.p1,
"p2": item.p2,
"p3": item.p3,
"timestamp": item.date,
]
}
let batchInsertRequest = NSBatchInsertRequest(
entity: Item.entity(),
objects: mapped
)
batchInsertRequest.resultType = NSBatchInsertRequestResultType.objectIDs
do {
let objectIDs = try self.moc.execute(batchInsertRequest)
print(objectIDs)
} catch {
let nsError = error as NSError
fatalError("Unresolved error \(nsError), \(nsError.userInfo)")
}
}
self.buffer.removeAll()
}The Case Study
To truly see the mind-boggling effects of a buffer and batched insert I’ve built a simple app that does… just that. It has a configurable buffer in a form of a very sexy slider. There are other sliders but this one is my favourite.
The hypothesis is that increasing the buffer size should limit the amount of hard-disk interactions. Making the buffer small should, in effect, increase the usage of the hard-disk and should bring us closer to the issue I was having in the first place. Even though the amount of actual data inserted into the database did not change and remains an almost constant.
By manipulating the buffer size we get a nifty graph showing the relationship between the frequent inserts, save operations and disk-usage.
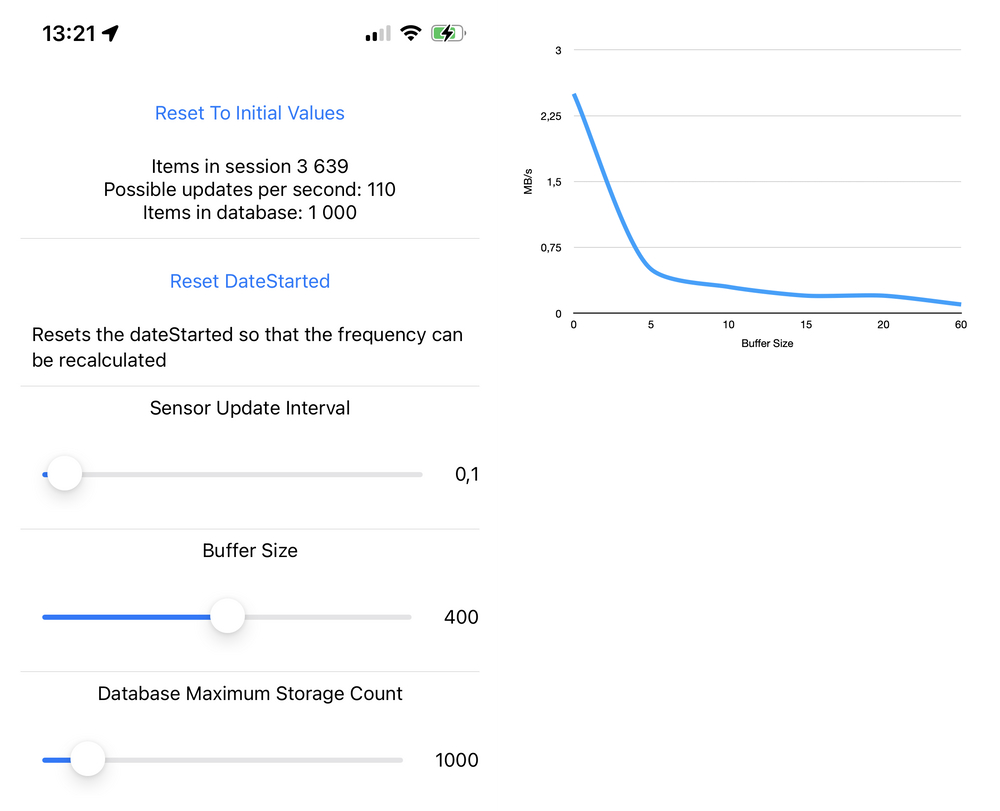
Conclusion?
Save infrequently, use buffers in RAM. Hard-disk access is still a luxury car. Just a faster one. With an engine that doesn’t scream. Oh… and the car has a bar in it. Still… it’s just a car.
Having a super duper fast SSD should not excuse the programmer from optimising the code. In the end our applications run on hardware people paid real money for.
References

Krzysztof Pawłowski is a live-long coder turned “developer”. “Initiated” on his trusty Atari XL. Sold his soul to Apple years later just in time for the iPhone. Does mainly iOS development since and dabbles (poorly) in graphics engine’s coding. Ask him anything. He won’t know… but he’ll try to answer xd